Overview
Data lineage gives visibility into where data comes from and where it goes. As a data pro, having access to lineage allows for quicker root cause analysis and better visualization of your data process. Understanding data lineage is valuable for multiple reasons:
- Understanding the origin of data
- Quickly identifying sources of error
- Providing audit trails for better track data assets
- Improving business performance by improving business analysis
- Managing data governance compliance and much more!
Validatar provides a way to view a data source's table and column-level lineage in the Explorer. To view lineage, you must create a lineage ingestion process for a data source. Choose between File or SQL Query ingestion.
Consider where you plan to get the lineage data from when choosing an ingestion process. Use a SQL query if your lineage data is coming from one source, stored in a database. Use File ingestion if your data is coming from multiple sources or is not stored in a database.
Before creating and executing a lineage ingestion process, make sure you ingest schema metadata for the data source.
File Process
The File Ingestion process consists of 4 steps:
- Create a New File Process
- Generate the Import File
- Fill out the spreadsheet
- Upload the Import File
Create a New File Process
To create a new file process:
- Navigate to Settings > Lineage Metadata.
- Click the New Process drop-down, and select New File Process.
- Enter the process name and optional description.
- Click Save.
Generating a File
The lineage file holds the source to target mapping information for your data process. Generating the import file from Validatar provides all the column headers needed to ingest lineage. Existing file processes can create the import file from previous ingestion. This option is disabled for new file processes.
To generate the import file:
- In the new file process, click Generate Import File.
- Select Headers Only and click Download File.
The generated import file has the following columns:
| Source Information | Target Information | Lineage Notes |
|---|---|---|
|
|
|
* not required
Each row represents a source to target data mapping in your data process down to the column level meaning each column in a table will have a record in the file. For table level mapping, you will leave the source.column_name and target.column_name fields blank.
Lineage_transformation will show the user what data transformation occurred on the target object. Lineage_notes will show any additional notes on the target object. Both can be viewed on the data object in the Explorer.
.png)
The above is an example of a source database named "SalesDemo" located on server 10.0.1.237 mapped to a cloud database named "Sales" located in Snowflake. Notice that the first record leaves source.column_name and target.column_name blank because it is table level mapping of the "Address" table to the "LOAD_ADDRESS_DEMOLT2019" table. The remaining Address records are column-level mappings.
Once the mapping is complete, it's time to upload the file and execute the lineage process.
Uploading a File
To upload a file:
- In the new file process, click Upload Import File.
- Select the file.
- Click Import.
- Click Save.
Query Process
Create a New Query Process
To create a new query process:
- Navigate to Settings > Lineage Metadata.
- Click the New Process drop-down, and select New Query Process.
- Enter the process name and optional description.
- Add the Lineage Metadata Connection.
- Configure the ingestion SQL.
- Set the Refresh Schedule (optional).
- Click Save.
Lineage Metadata Connection
The first step in configuring the query is to create the lineage metadata connection. You cannot use existing data source connections for this step. Instead, you will have to define the connection on the process configuration page.
For more help on configuring a connection, view Creating a Data Source.
Configure Ingestion SQL
The SQL query references the same columns as the file process. Validatar requires that all columns in the query be aliased using Validatar's field names. Copy the following query template to assist with building the query.
select
[replace] as [source.server_name],
[replace] as [source.database_name],
[replace] as [source.schema_name],
[replace] as [source.table_name],
[replace] as [source.column_name],
[replace] as [target.server_name],
[replace] as [target.database_name],
[replace] as [target.schema_name],
[replace] as [target.table_name],
[replace] as [target.column_name],
[replace] as [lineage_transformation],
[replace] as [lineage_notes]
from [replace]Swap your column names for the [replace] tag, and remember to keep those columns aliased with Validatar's field names. You can also find this template by clicking Copy Template Query in the SQL ingestion pop-up window.
This is the simplest form of the ingestion query. In reality, your lineage data may come from multiple tables that need to be joined together. In this example, we'll look at a sample lineage query for a data warehouse built using WhereScape. This query will pull the lineage of Dimension tables using the WhereScape repository.
SELECT distinct
'10.0.1.237' as 'source.server_name',
dc.dc_odbc_source as 'source.database_name',
sdt.dt_schema as 'source.schema_name',
dc_src_table AS 'source.table_name',
'' as 'source.column_name',
'10.0.1.237' as 'target.server_name',
dc.dc_odbc_source as 'target.database_name',
dt.dt_schema as 'target.schema_name',
dt_table_name AS 'target.table_name',
'' as 'target.column_name',
'' as 'lineage_transformation',
'' as 'lineage_notes'
FROM dbo.ws_dim_tab d
INNER JOIN ws_dim_col on dc_obj_key = dt_obj_key
inner join ws_obj_object on oo_obj_key = dt_obj_key
inner join ws_dbc_target dt on dt_target_key = oo_target_key or case when oo_target_key = 0 then 'dbo' else '' end = dt.dt_schema
inner join ws_dbc_connect dc on dt.dt_connect_key = dc.dc_obj_key
inner join ws_obj_object so on so.oo_name = dc_src_table
inner join ws_dbc_target sdt on sdt.dt_target_key = so.oo_target_key or case when so.oo_target_key = 0 then 'dbo' else '' end = sdt.dt_schema
inner join ws_dbc_connect sdc on sdt.dt_connect_key = dc.dc_obj_key
WHERE COALESCE(LTRIM(RTRIM(dc_src_table)),'') <> ''This query finds the database, schema, and table names by joining the source and target objects on their respective object keys using WhereScape tables. Since this query is for table-level lineage, the source.column_name and target.column_name columns are left empty. You would union similar scripts to get the lineage for other object types.
Similar to the file ingestion, lineage_transformation and lineage_notes are not required in the ingestion query.
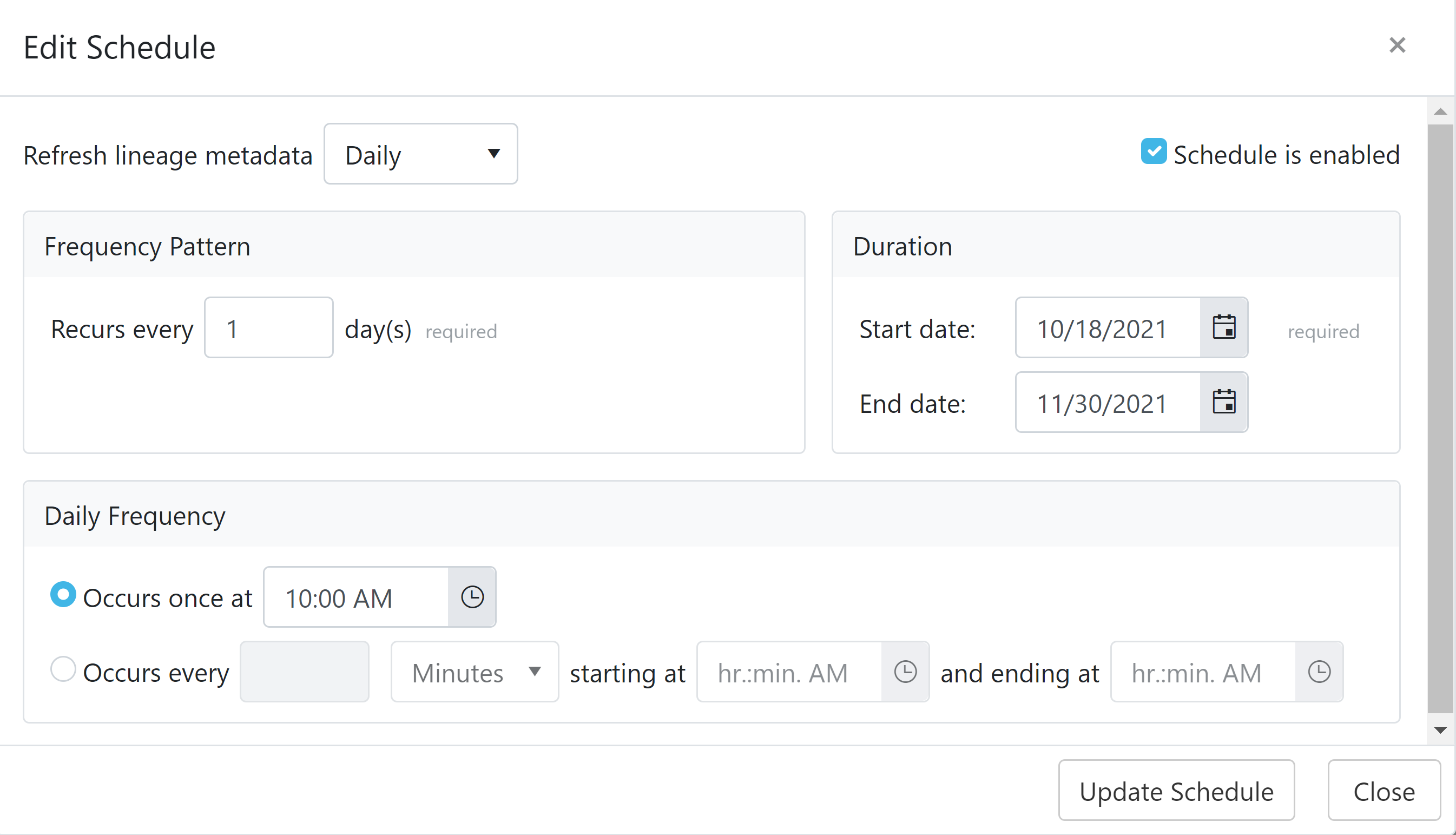
Set Refresh Schedule
Set a refresh schedule to ensure the most recent lineage data is in Validatar. Choose the frequency and duration of the schedule.
Possible Errors
The following errors may occur while trying to ingest lineage metadata.
| Error | Description |
|---|---|
| Target object was not found | There was no matching table or column found in the target data source. |
| Source object was not found | There was no matching table or column found in the source data source. |
| Duplicate Mapping | The file or query contains a duplicate mapping. Make sure that a source to target mapping only appears once. |
| Invalid Column | The file or query contains an unknown column. Remove any invalid columns. |